I am a research assistant and PhD candidate at the University of Victoria,
where I am chasing my wildest dreams in the field of computer vision.
I am working in Computer Vision Lab under Prof. Alexandra Branzan Albu supervision, and
I am always on the lookout for new and exciting ways to make machines see like a human.
My ultimate goal is to make our lives more effortless and cooler by
developing cutting-edge techniques and algorithms for computer vision systems.


Imbalanced Human Action Recognition Dataset
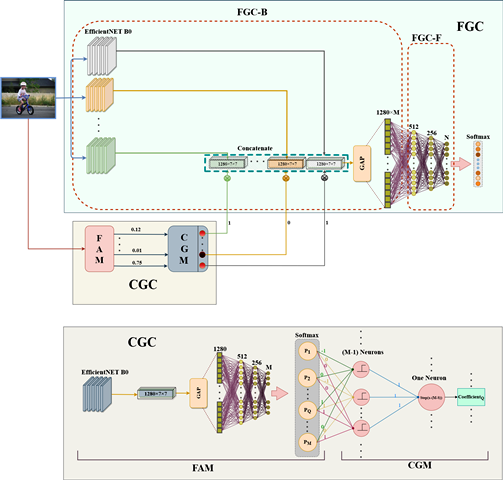
In still image human action recognition, existing studies have mainly leveraged extra bounding box information along with class labels to mitigate the lack of temporal information in still images. However, preparing additional annotations such as human and object bounding boxes is time-consuming and also prone to human errors because these annotations are prepared manually. In this paper, we propose a two-phase multi-expert classification method for human action recognition by means of super-class learning and without any extra information. Specifically, a coarse-grained phase selects the most relevant fine-grained experts. Then, the fine-grained experts encode the intricate details within each super-class so that the inter-class variation increases. In the proposed approach, to choose the best configuration for each super-class and characterize inter-class dependency between different action classes, we propose a novel Graph-Based Class Selection (GCS) algorithm. Moreover, the proposed method copes with long-tailed distribution, which the existing studies have not addressed in action recognition. Extensive experimental evaluations are conducted on various public human action recognition datasets, including Stanford40, Pascal VOC 2012 Action, BU101+, and IHAR datasets. The experimental results demonstrate that the proposed method yields promising improvements. To be more specific, in IHAR, Sanford40, Pascal VOC 2012 Action, and BU101+ benchmarks, the proposed approach outperforms the state-of-the-art studies by 8.92%, 0.41%, 0.66%, and 2.11 % with much less computational cost and without any auxiliary annotation information. Besides, it is proven that in addressing action recognition with long-tailed distribution, the proposed method outperforms its counterparts by a significant margin.
Action Recognition in Still Image Using Transfer Learning
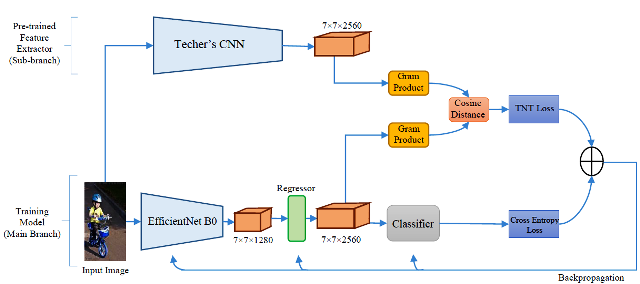
Lack of training data and small datasets is one of the main challenges in human action recognition in still images. For this reason, training a network from scratch does not lead to good results just by using this little training data. Hence, many existing methods use the transfer learning techniques such as fine-tuning a pre-trained network with initial weights from ImageNet. It is important to note that some of the weights obtained from ImageNet are not suitable for human action recognition tasks. On the other hand, in fine-tuning the network, suitable initial weights for human action recognition may be changed. This paper proposes a method called To Transfer or Not To Transfer (TNT) based on knowledge distillation. In this method, a none trainable teacher with ImageNet weights is used to train a light student network for action recognition tasks. In order to transfer relevant knowledge and not to transfer insufficient knowledge from teacher to student, a To Transfer or Not To Transfer Loss (TNTL) function is introduced in this paper. The proposed method is evaluated on Stanford 40 and Pascal VOC datasets, and the results show the superiority of this method over existing methods that use more parameters.
In recent years, human action recognition in still images has become a challenge in computer vision. Most methods in this field use annotations such as human and object bounding boxes to determine human-object interaction and pose estimation. Preparing these annotations is time-consuming and costly. In this paper, an ensembling-based method is presented to avoid any additional annotations. According to this fact that a network performance on fewer classes of a dataset is often better than its performance on whole classes; the dataset is first divided into four groups. Then these groups are applied to train four lightweight Convolutional Neural Networks (CNNs). Consequently, each of these CNNs will specialize on a specific subset of the dataset. Then, the final convolutional feature maps of these networks are concatenated together. Moreover, a Feature Attention Module (FAM) is trained to identify the most important features among concatenated features for final prediction. The proposed method on the Stanford40 dataset achieves 86.86% MAP, which indicates this approach can obtain promising performance compared with many existing methods that use annotations.
Segmentation of road scenes is a crucial problem in computer vision for autonomous driving. For instance, in order to navigate, an autonomous vehicle needs to determine the drivable area ahead and determine its position on the road with respect to the lane markings. However, the problem is challenging due to the presence of environmental factors like noise, darkness, camera shake, especially in bad weather conditions. In this paper, we present a network with two parts for road segmentation under environmental factors, also in order to simulate environmental factors, we use processed images from KITTI and CamVid datasets. This method is implemented on NVDIA GEFORCE MX150 GPU (4G RAM) and the accuracy arrives at 90.75% under environmental factors.
